





日本経済新聞社は、人工知能(AI)を使った記事作成などのサービスを研究しています。このたび始まった『決算サマリー』は、上場企業が発表する決算データをもとにAIが文章を作成。適時開示サイトでの公表後すぐに、売上や利益などの数字とその背景などの要点をまとめて配信します。元データである企業の開示資料から文章を作成し、配信するまでは完全に自動化し、人によるチェックや修正などは一切行いません。作成した『決算サマリー』は当面、ベータ版(試用版)との位置づけですが、『日本経済新聞 電子版』や『日経テレコン』などのコンテンツとして恒常的に提供していきます。
速い
発表後、数分で記事が出てきます。
多い
上場企業(約3600社)の大半に対応します。
完全自動
AIのみで自動作成、人は関与しません。

![]()
日本経済新聞社
1876年、現在の日本経済新聞を創刊。新聞制作システムの導入や会員制情報サービス『日経テレコン』、日経電子版の創刊など、最先端の技術をメディアに活用した事業に取り組んできた。今回のプロジェクトは社内のエンジニアが中心となって立ち上げた。AIの”教師"にあたるデータとして記事アーカイブを使用し、東大松尾研やILUと協力し「記者が決算情報をどのように読み、記事にするか」をAIに学習させた。


日経は創刊140年を超える新聞社ですが、『日本経済新聞 電子版』の創刊や英フィナンシャル・タイムズの買収など、時代に合わせて変化を続けています。私たちは最先端のデジタルテクノロジーを自ら開発し、駆使するメディア企業を目指しています。AIの活用にも取り組んでおり、今回始まった『決算サマリー』もそうした取り組みのひとつです。

AI記事プロジェクトの最初の応用分野として選んだのは、企業の決算発表です。日本国内の上場企業は約3600社あり、記者による取材・執筆に加えてAIを使うことで、より多く、早く企業の動向をお伝えすることができます。

今回のプロジェクトは日経のエンジニアが主導。AI研究で実績のある東京大学の松尾豊研究室と共同研究を始め、決算データから要点を抽出する日経のノウハウをAIに学習させることで、AIによる記事生成の実現性が高まりました。そこで実用システムの開発に向け、日本語の意味を理解するAI技術に強みを持つ言語理解研究所(ILU、徳島県徳島市)と共同開発を進め、同社の独自技術により今回のベータ版にこぎつけることができました。
当面はベータ版との位置付けです。決して完璧ではありませんが、表示の仕方やAIの性能などを適宜見直し、向上させていきます。今後にご期待くださいますよう、お願い申し上げます。
※この文章は、まだ人間が書いています

抽出フロー
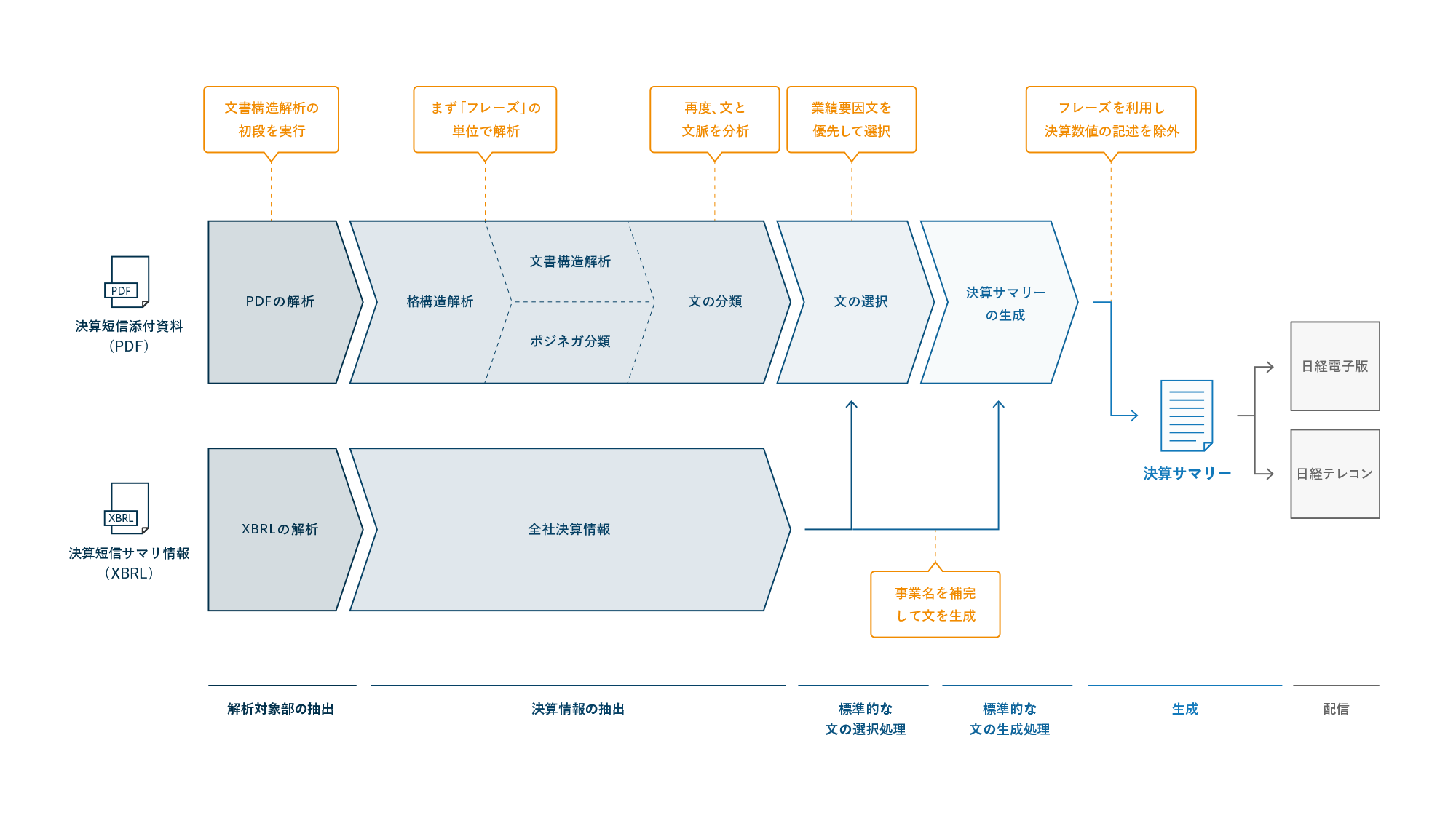

アルゴリズム
決算短信や過去の日経記事の各文から、業績変動の要因を言及する文(業績要因文)を抽出するアルゴリズムを考案しました。
セグメントの重要度、各文の極性値、各文の重要度を計算し、業績要因文を2文抽出します。決算短信とは、企業が四半期ごとに開示する決算レポートです。
\[y(S_l)\]
: 文\[l\]に含まれるセグメントの重要度
説明変数:売上高/利益の総変動量に対する各事業の変動量は今期-前年同期、今期-前期の変動量を利用します。
| セグメント 売上高 |
売上高 | セグメント 利益 |
利益 | |
|---|---|---|---|---|
| 今期 | \[s_c\] | \[S_c\] | \[r_c\] | \[R_c\] |
| 前年同期 | \[s_p\] | \[S_p\] | \[r_p\] | \[R_p\] |
| 前期 | \[s_f\] | \[S_f\] | \[r_f\] | \[R_f\] |
目的変数:事業セグメントの記事掲載における重要度は記事に事業名又はその略称が記述されているかを判定します。
\[ y = \begin{cases} 1 & if \max_{W_t} dice(S(W_s), S(W_t)) > threshold\\ 0 \end{cases} \]得られた学習データ集合をもとに、サポートベクターマシンによる記事掲載の有無の推定や、 サポートベクター回帰による記事掲載確率の連続値の推定を行っています。
\[v(l)\] : 文\[l\]に含まれる単語対の極性値
売上高・利益が増加した場合その業績要因文は正の極性を持つ場合が多く、減少した場合負の極性を持つ場合が多いと考えられます。
決算記事の各文章を係り受け解析し、係り受け元と係り受け先の単語対\[(i,j)\]について、売上高・利益増加時の出現回数\[p_i,_j\]から減少時の出現回数\[n_i,_j\]を引いた値を総出現回数で除すことでその単語対の極性値\[v_i,_j\]を算出しています。
未出現の単語対についても対応するために、下図のようにNMF(Non-Negative Matrix Factorization)により極性値の推定を行っています。
| 増える\[v_1\] | 増加\[v_2\] | 減る\[v_3\] | 減少\[v_4\] | |
|---|---|---|---|---|
| 販売台数\[u_1\] | 0.8 | 0.7 | -0.8 | -0.9 |
| 販管費\[u_2\] | -0.8 | -0.9 | 0.8 | 0.9 |
| 出店数\[u_3\] | 0.9 | 0.8 | -0.9 | ? |
\[e(l)\] : 文\[l\]に含まれる単語群の重要度
各単語の重要度を各企業の決算記事におけるtf-idf値で獲得します。
各単語の重要度平均を\[e(l)\]として算出します。
重要単語は当該企業の過去の決算記事において頻出し、かつ他企業の決算記事には出現しにくい単語であるという仮説から、
単語\[t\]の企業\[c\]における重要度\[e_t,_c\]をtf-idf値で表現しています。
\[
\begin{align}
e_t,_c &= tf_t,_c \cdot idf_t\\
tf_t,_c &= \frac{n_t,_c}{\sum_k n_t,_c}\\
idf_t &= log \frac{N}{N_t}
\end{align}
\]
※このアルゴリズムはプロトタイプに使用したもので、決算サマリーサービスに当初は組み込まれておりません。今後、精度向上に取り組み導入する予定です。
実験結果
セグメントの重要度判定とNMFによる極性推定の有効性を確認することができました。
| 適合率 | 再現率 | F値 | |
|---|---|---|---|
| (A)単語の重要度判定+極性辞書による極性判定 | 0.53 | 0.57 | 0.55 |
| (B)(A)+セグメントの重要度判定 | 0.57 | 0.61 | 0.59 |
| (C)(A)+NMFに極性推定 | 0.58 | 0.62 | 0.60 |
| (D)(A)+セグメントの重要度判定+NMFに極性推定 | 0.66 | 0.71 | 0.68 |
※この実験結果はプロトタイプによるものです。決算サマリーサービスに当初は組み込まれておりません。今後、精度向上に取り組み導入する予定です。
[出典]磯沼 大, 藤野 暢, 浮田 純平, 村上 遥, 浅谷 公威, 森 純一郎, 坂田 一郎, 業績変動を考慮した決算短信からの重要文抽出, 研究報告自然言語処理(NL), 2016-NL-227, no.6, pp.1-6, 2016

Q1 : 通常の記事とは何が違うのですか
A1 : 『決算サマリー』は、企業が開示した決算資料の要点を人工知能(AI)がまとめたものです。作成はすべてAIが行い、人は一切関与していません。記者が書く通常の記事と異なります。
Q2 : 本サービスにおける「AIの機能」とは、どのようなものをさすのですか
A2 : 企業の開示した資料をもとに、要点を抽出し、日経の所定の表現に合わせて文章を作成します。
Q3 : 他の記事に比べて読みづらくなっている箇所があるのですが
A3 : 当面はベータ版(Beta)として運用しています。今後、改善を続けますのでご期待ください。
Q4 : 元となるデータはどのようなものを使っていますか
A4 : 東京証券取引所の運営する適時開示サイト『TDネット』に企業が公開した情報を読み込んでいます。
Q5 : 自動作成の対象はどのように判断しているのですか
A5 : TDネットで決算情報を開示している企業を対象に、AIが処理しています。ただし、開示されたデータの形式などの問題でAIが処理しきれないものもあります。
Q6 : 自動作成したコンテンツに関する権利はどこに帰属していますか
A6 : 日経に帰属しております。二次利用のルールなどはこちらをご覧ください。
Q7 : 決算サマリーは投資判断に役立ちますか
A7 : 投資などへのご利用はご自身の判断と責任でお願いします。詳しくは、日経電子版の注意事項をご覧ください。
Q8 : 通常の記事とはどのように見分ければ良いでしょうか
A8 : 記事のタイトルや末尾などに自動で生成された旨を記載しています。
Q9 : どこで見ることができますか
A9 : 日経電子版内、日経会社情報DIGITALの「決算サマリー」コーナーや会員制ビジネス情報サービスの「日経テレコン」で見ることができます。「日本経済新聞」紙面には使われていません。